

How To Find The Difference Between Two Points
How to test for differences between samples
Oftentimes we would want to compare sets of samples. Such comparisons include if wild-type samples accept different expression compared to mutants or if good for you samples are dissimilar from disease samples in some measurable feature (blood count, gene expression, methylation of sure loci). Since there is variability in our measurements, we need to accept that into account when comparing the sets of samples. We can simply decrease the means of two samples, but given the variability of sampling, at the very to the lowest degree we demand to decide a cutoff value for differences of ways; small differences of means tin can be explained past random chance due to sampling. That ways nosotros need to compare the departure nosotros become to a value that is typical to go if the difference betwixt two grouping means were merely due to sampling. If you followed the logic above, hither we actually introduced ii core ideas of something chosen "hypothesis testing", which is just using statistics to determine the probability that a given hypothesis (Ex: if 2 sample sets are from the same population or non) is true. Formally, expanded version of those two cadre ideas are every bit follows:
- Decide on a hypothesis to test, often called the "null hypothesis" (\(H_0\)). In our case, the hypothesis is that there is no divergence betwixt sets of samples. An "alternative hypothesis" (\(H_1\)) is that at that place is a divergence between the samples.
- Decide on a statistic to examination the truth of the zero hypothesis.
- Calculate the statistic.
- Compare information technology to a reference value to establish significance, the P-value. Based on that, either reject or not reject the null hypothesis, \(H_0\).
Randomization-based testing for divergence of the means
There is one intuitive manner to go nearly this. If we believe there are no differences betwixt samples, that means the sample labels (test vs. control or healthy vs. affliction) have no meaning. So, if we randomly assign labels to the samples and calculate the difference of the ways, this creates a null distribution for \(H_0\) where we can compare the real difference and mensurate how unlikely it is to get such a value under the expectation of the null hypothesis. We can summate all possible permutations to calculate the zero distribution. However, sometimes that is not very feasible and the equivalent approach would be generating the nada distribution past taking a smaller number of random samples with shuffled group membership.
Below, we are doing this process in R. Nosotros are commencement simulating 2 samples from two different distributions. These would exist equivalent to factor expression measurements obtained under different conditions. Then, we calculate the differences in the means and exercise the randomization procedure to go a null distribution when we assume in that location is no difference between samples, \(H_0\). We then calculate how ofttimes we would get the original departure we calculated under the assumption that \(H_0\) is true. The resulting null distribution and the original value is shown in Figure 3.9.
set.seed(100) gene1=rnorm(30,mean= 4,sd= 2) gene2=rnorm(xxx,mean= 2,sd= 2) org.unequal=hateful(gene1)- mean(gene2) gene.df=information.frame(exp= c(gene1,gene2), group= c( rep("examination",30),rep("command",30) ) ) exp.zippo <- do(1000) * diff(mosaic:: mean(exp ~ shuffle(group), data=gene.df)) hist(exp.goose egg[,1],xlab= "null distribution | no difference in samples", main= expression(paste(H[0]," :no departure in ways") ), xlim= c(- 2,2),col= "cornflowerblue",border= "white") abline(five= quantile(exp.zilch[,ane],0.95),col= "red" ) abline(v=org.diff,col= "blue" ) text(x= quantile(exp.nada[,1],0.95),y= 200,"0.05",adj= c(1,0),col= "red") text(10=org.diff,y= 200,"org. unequal.",adj= c(i,0),col= "blue") 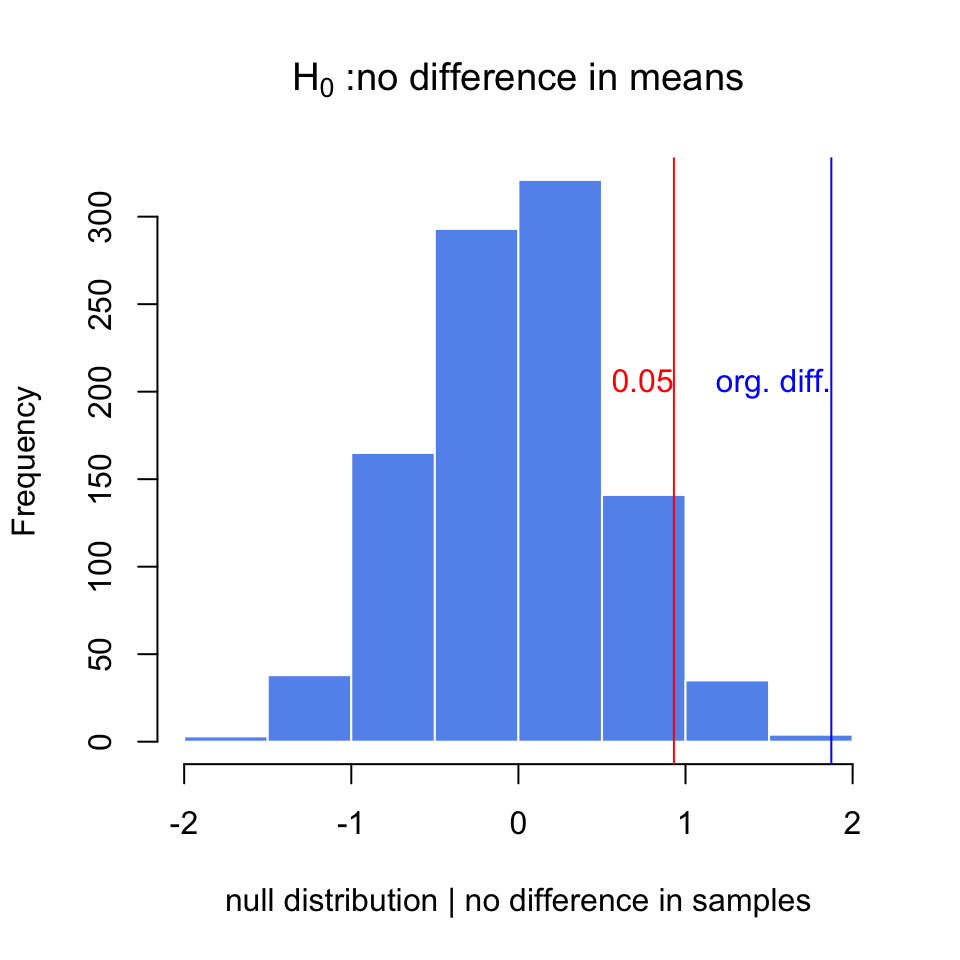
Effigy 3.9: The zero distribution for differences of means obtained via randomization. The original deviation is marked via the blueish line. The cerise line marks the value that corresponds to P-value of 0.05
p.val=sum(exp.null[,1]>org.diff)/ length(exp.null[,1]) p.val ## [1] 0.001 Afterward doing random permutations and getting a null distribution, information technology is possible to get a confidence interval for the distribution of difference in means. This is simply the \(2.5th\) and \(97.fifth\) percentiles of the null distribution, and directly related to the P-value calculation higher up.
Using t-exam for difference of the means between ii samples
We can as well summate the difference between means using a t-test. Sometimes we will have too few data points in a sample to exercise a meaningful randomization exam, also randomization takes more time than doing a t-test. This is a test that depends on the t distribution. The line of thought follows from the CLT and we can show differences in ways are t distributed. In that location are a couple of variants of the t-test for this purpose. If we assume the population variances are equal we can use the following version
\[t = \frac{\bar {X}_1 - \bar{X}_2}{s_{X_1X_2} \cdot \sqrt{\frac{one}{n_1}+\frac{1}{n_2}}}\] where \[s_{X_1X_2} = \sqrt{\frac{(n_1-one)s_{X_1}^2+(n_2-one)s_{X_2}^2}{n_1+n_2-2}}\] In the first equation above, the quantity is t distributed with \(n_1+n_2-two\) degrees of freedom. We tin can calculate the quantity and then employ software to look for the percentile of that value in that t distribution, which is our P-value. When we cannot presume equal variances, we use "Welch's t-test" which is the default t-test in R and also works well when variances and the sample sizes are the same. For this test nosotros calculate the following quantity:
\[t = \frac{\overline{X}_1 - \overline{Ten}_2}{s_{\overline{10}_1 - \overline{Ten}_2}}\] where \[s_{\overline{X}_1 - \overline{X}_2} = \sqrt{\frac{s_1^2 }{ n_1} + \frac{s_2^ii }{n_2}}\]
and the degrees of freedom equals to
\[\mathrm{d.f.} = \frac{(s_1^ii/n_1 + s_2^2/n_2)^2}{(s_1^2/n_1)^2/(n_1-1) + (s_2^2/n_2)^2/(n_2-1)} \]
Luckily, R does all those calculations for united states of america. Beneath we volition show the use of t.test() function in R. We will use it on the samples we false above.
# Welch's t-test stats:: t.test(gene1,gene2) ## ## Welch 2 Sample t-test ## ## data: gene1 and gene2 ## t = iii.7653, df = 47.552, p-value = 0.0004575 ## alternative hypothesis: truthful departure in means is non equal to 0 ## 95 pct conviction interval: ## 0.872397 2.872761 ## sample estimates: ## mean of ten mean of y ## 4.057728 two.185149 # t-test with equal variance supposition stats:: t.test(gene1,gene2,var.equal= True) ## ## Two Sample t-test ## ## data: gene1 and gene2 ## t = 3.7653, df = 58, p-value = 0.0003905 ## alternative hypothesis: true difference in ways is not equal to 0 ## 95 percentage confidence interval: ## 0.8770753 2.8680832 ## sample estimates: ## mean of 10 mean of y ## 4.057728 ii.185149 A final give-and-take on t-tests: they by and large presume a population where samples coming from them have a normal distribution, even so it is been shown t-test can tolerate deviations from normality, specially, when 2 distributions are moderately skewed in the same direction. This is due to the central limit theorem, which says that the means of samples will exist distributed normally no thing the population distribution if sample sizes are big.
Multiple testing correction
We should think of hypothesis testing every bit a non-error-gratis method of making decisions. There will exist times when we declare something significant and accept \(H_1\) but nosotros will be wrong. These decisions are also called "false positives" or "false discoveries", and are also known equally "type I errors". Similarly, we can fail to reject a hypothesis when nosotros actually should. These cases are known as "faux negatives", besides known equally "type 2 errors".
The ratio of true negatives to the sum of true negatives and false positives (\(\frac{TN}{FP+TN}\)) is known as specificity. And nosotros commonly want to decrease the FP and get higher specificity. The ratio of true positives to the sum of truthful positives and false negatives (\(\frac{TP}{TP+FN}\)) is known as sensitivity. And, again, we usually want to decrease the FN and get higher sensitivity. Sensitivity is also known as the "ability of a test" in the context of hypothesis testing. More powerful tests will be highly sensitive and will have fewer type Ii errors. For the t-test, the power is positively associated with sample size and the upshot size. The larger the sample size, the smaller the standard fault, and looking for the larger effect sizes volition similarly increase the power.
The general summary of these different decision combinations are included in the tabular array below.
| \(H_0\) is TRUE, [Gene is Non differentially expressed] | \(H_1\) is True, [Factor is differentially expressed] | ||
|---|---|---|---|
| Take \(H_0\) (claim that the gene is non differentially expressed) | True Negatives (TN) | Faux Negatives (FN) ,type II error | \(m_0\): number of truly null hypotheses |
| reject \(H_0\) (claim that the gene is differentially expressed) | False Positives (FP) ,type I error | True Positives (TP) | \(m-m_0\): number of truly alternative hypotheses |
We expect to make more blazon I errors as the number of tests increment, which means nosotros volition turn down the null hypothesis by mistake. For example, if we perform a test at the 5% significance level, there is a 5% take a chance of incorrectly rejecting the null hypothesis if the zero hypothesis is truthful. Nevertheless, if we make 1000 tests where all null hypotheses are truthful for each of them, the average number of wrong rejections is 50. And if nosotros employ the rules of probability, there is almost a 100% chance that nosotros will take at to the lowest degree i wrong rejection. There are multiple statistical techniques to prevent this from happening. These techniques generally push button the P-values obtained from multiple tests to higher values; if the private P-value is low plenty it survives this process. The simplest method is merely to multiply the individual P-value (\(p_i\)) by the number of tests (\(m\)), \(thousand \cdot p_i\). This is chosen "Bonferroni correction". However, this is likewise harsh if you have thousands of tests. Other methods are developed to remedy this. Those methods rely on ranking the P-values and dividing \(m \cdot p_i\) past the rank, \(i\), :\(\frac{m \cdot p_i }{i}\), which is derived from the Benjamini–Hochberg procedure. This procedure is adult to control for "False Discovery Rate (FDR)" , which is the proportion of simulated positives among all meaning tests. And in practical terms, we become the "FDR-adjusted P-value" from the procedure described higher up. This gives u.s.a. an estimate of the proportion of fake discoveries for a given test. To elaborate, p-value of 0.05 implies that five% of all tests will be false positives. An FDR-adjusted p-value of 0.05 implies that five% of pregnant tests will be false positives. The FDR-adapted P-values will result in a lower number of false positives.
Ane final method that is as well popular is chosen the "q-value" method and related to the method in a higher place. This procedure relies on estimating the proportion of truthful null hypotheses from the distribution of raw p-values and using that quantity to come upward with what is called a "q-value", which is also an FDR-adapted P-value (Storey and Tibshirani 2003). That tin can be practically defined every bit "the proportion of significant features that plough out to be false leads." A q-value 0.01 would mean 1% of the tests chosen significant at this level will be truly goose egg on average. Within the genomics customs q-value and FDR adapted P-value are synonymous although they can exist calculated differently.
In R, the base of operations function p.accommodate() implements most of the p-value correction methods described above. For the q-value, we can utilize the qvalue package from Bioconductor. Below we demonstrate how to utilize them on a gear up of fake p-values. The plot in Figure 3.10 shows that Bonferroni correction does a terrible job. FDR(BH) and q-value approach are better but, the q-value approach is more than permissive than FDR(BH).
library(qvalue) information(hedenfalk) qvalues <- qvalue(hedenfalk$p)$q bonf.pval=p.accommodate(hedenfalk$p,method = "bonferroni") fdr.adj.pval=p.adjust(hedenfalk$p,method = "fdr") plot(hedenfalk$p,qvalues,pch= 19,ylim= c(0,1), xlab= "raw P-values",ylab= "adjusted P-values") points(hedenfalk$p,bonf.pval,pch= 19,col= "ruby") points(hedenfalk$p,fdr.adj.pval,pch= xix,col= "blue") legend("bottomright",legend= c("q-value","FDR (BH)","Bonferroni"), fill= c("blackness","blue","red")) 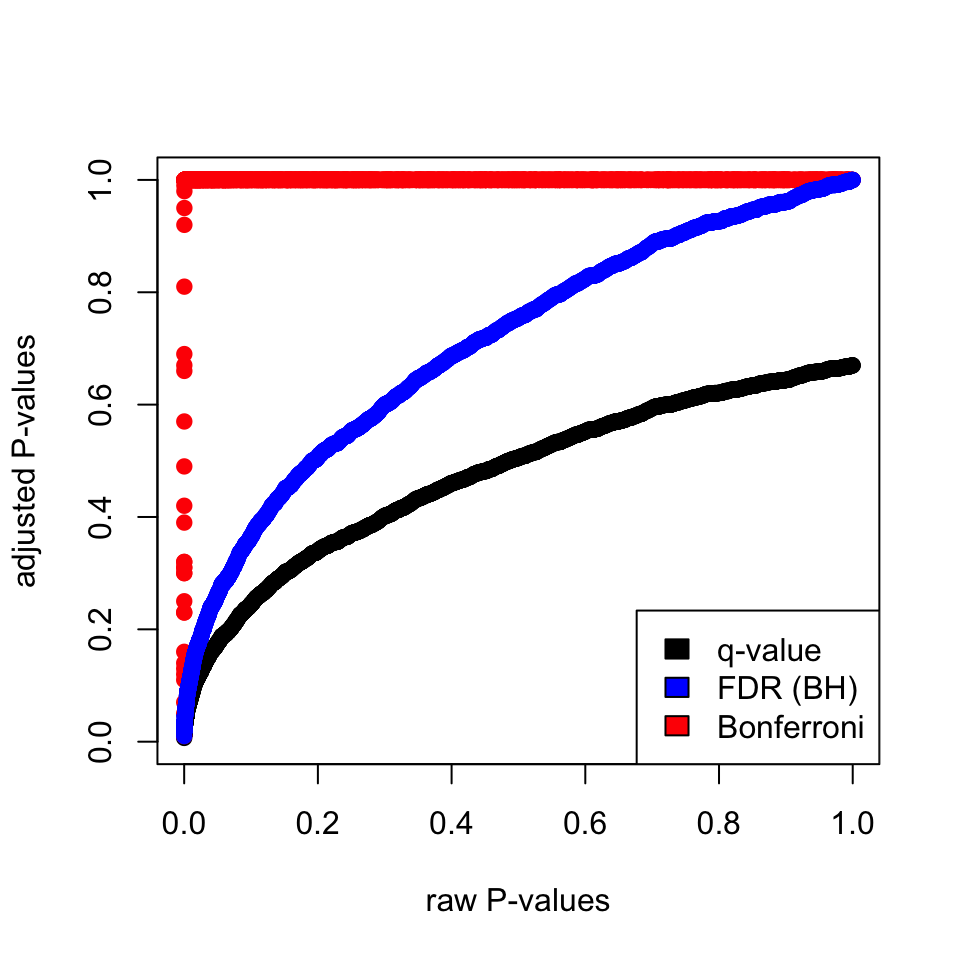
FIGURE 3.10: Adjusted P-values via different methods and their human relationship to raw P-values
Moderated t-tests: Using information from multiple comparisons
In genomics, we usually do not do one test but many, as described above. That means we may be able to use the data from the parameters obtained from all comparisons to influence the individual parameters. For example, if yous take many variances calculated for thousands of genes across samples, you tin can force individual variance estimates to compress toward the hateful or the median of the distribution of variances. This usually creates amend functioning in private variance estimates and therefore better performance in significance testing, which depends on variance estimates. How much the values are shrunk toward a mutual value depends on the exact method used. These tests in general are called moderated t-tests or shrinkage t-tests. One approach popularized by Limma software is to use so-called "Empirical Bayes methods". The master conception in these methods is \(\hat{V_g} = aV_0 + bV_g\), where \(V_0\) is the groundwork variability and \(V_g\) is the individual variability. Then, these methods estimate \(a\) and \(b\) in various ways to come with a "shrunk" version of the variability, \(\hat{V_g}\). Bayesian inference tin can make use of prior knowledge to make inference well-nigh properties of the data. In a Bayesian viewpoint, the prior cognition, in this case variability of other genes, can be used to calculate the variability of an private gene. In our case, \(V_0\) would be the prior cognition we have on the variability of the genes and we use that knowledge to influence our guess for the individual genes.
Below nosotros are simulating a factor expression matrix with chiliad genes, and 3 test and 3 control groups. Each row is a cistron, and in normal circumstances we would similar to find differentially expressed genes. In this case, nosotros are simulating them from the aforementioned distribution, and then in reality we do non wait any differences. Nosotros and so use the adjusted standard error estimates in empirical Bayesian spirit but, in a very crude way. Nosotros merely shrink the gene-wise standard mistake estimates towards the median with equal \(a\) and \(b\) weights. That is to say, we add together the individual estimate to the median of the standard error distribution from all genes and divide that quantity by 2. So if nosotros plug that into the above formula, what we do is:
\[ \hat{V_g} = (V_0 + V_g)/2 \]
In the code below, we are avoiding for loops or apply family functions by using vectorized operations. The code beneath samples gene expression values from a hypothetical distribution. Since all the values come from the same distribution, we practice not look differences between groups. We then calculate moderated and unmoderated t-exam statistics and plot the P-value distributions for tests. The results are shown in Figure iii.xi.
set.seed(100) #sample data matrix from normal distribution gset=rnorm(3000,hateful= 200,sd= lxx) data=matrix(gset,ncol= 6) # set groups group1=ane : three group2=4 : 6 n1=3 n2=3 dx=rowMeans(data[,group1])- rowMeans(data[,group2]) require(matrixStats) # get the esimate of pooled variance stderr = sqrt( (rowVars(data[,group1])*(n1-1) + rowVars(data[,group2])*(n2-ane)) / (n1+n2-2) * ( 1 /n1 + 1 /n2 )) # do the shrinking towards median mod.stderr = (stderr + median(stderr)) / ii # moderation in variation # esimate t statistic with moderated variance t.mod <- dx / modern.stderr # calculate P-value of rejecting cypher p.mod = 2 * pt( - abs(t.mod), n1+n2-2 ) # esimate t statistic without moderated variance t = dx / stderr # calculate P-value of rejecting zippo p = 2 * pt( - abs(t), n1+n2-2 ) par(mfrow= c(1,2)) hist(p,col= "cornflowerblue",border= "white",main= "",xlab= "P-values t-test") mtext(paste("signifcant tests:",sum(p< 0.05)) ) hist(p.modern,col= "cornflowerblue",border= "white",main= "", xlab= "P-values modern. t-test") mtext(paste("signifcant tests:",sum(p.modernistic< 0.05)) ) 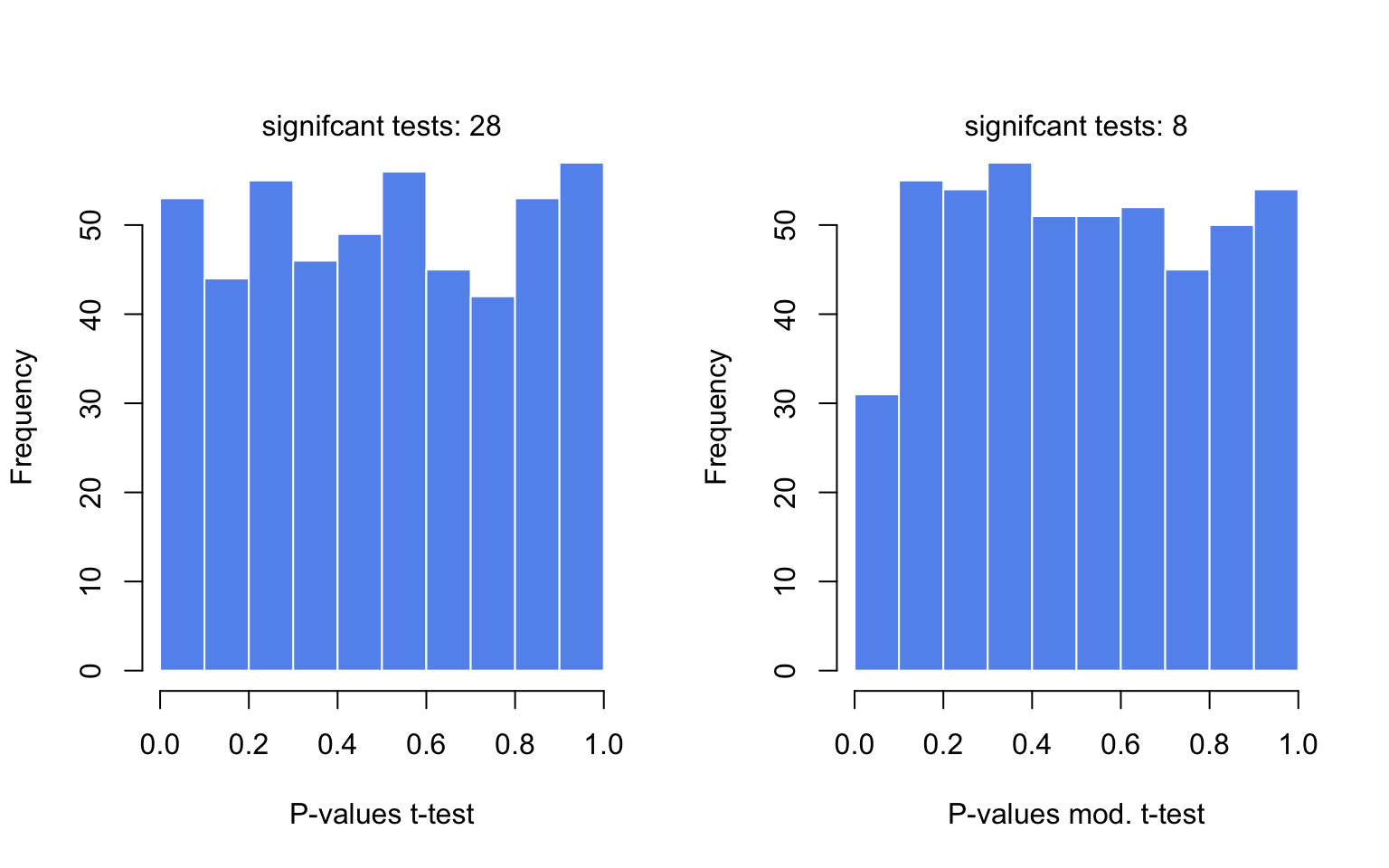
Figure 3.11: The distributions of P-values obtained past t-tests and moderated t-tests
Want to know more ?
- Basic statistical concepts
- "Cartoon guide to statistics" by Gonick & Smith (Gonick and Smith 2005). Provides central concepts depicted as cartoons in a funny but clear and accurate manner.
- "OpenIntro Statistics" (Diez, Barr, Çetinkaya-Rundel, et al. 2015) (Free e-volume http://openintro.org). This book provides cardinal statistical concepts in a clear and easy manner. It includes R code.
- Hands-on statistics recipes with R
- "The R book" (Crawley 2012). This is the primary R volume for anyone interested in statistical concepts and their application in R. It requires some background in statistics since the master focus is applications in R.
- Chastened tests
- Comparing of chastened tests for differential expression (De Hertogh, De Meulder, Berger, et al. 2010) http://bmcbioinformatics.biomedcentral.com/articles/x.1186/1471-2105-11-17
- Limma method developed for testing differential expression between genes using a moderated test (Smyth Gordon 2004) http://www.statsci.org/smyth/pubs/ebayes.pdf
References
De Hertogh, De Meulder, Berger, Pierre, Bareke, Gaigneaux, and Depiereux. 2010. "A Benchmark for Statistical Microarray Data Analysis That Preserves Actual Biological and Technical Variance." BMC Bioinformatics 11 (1): 17.
Smyth Gordon. 2004. "Linear Models and Empirical Bayes Methods for Assessing Differential Expression in Microarray Experiments." Statistical Applications in Genetics and Molecular Biology three (1): one–25.
Storey, and Tibshirani. 2003. "Statistical Significance for Genomewide Studies." Proc. Natl. Acad. Sci. U. S. A. 100 (16): 9440–5.

Source: https://compgenomr.github.io/book/how-to-test-for-differences-between-samples.html
Posted by: haneywhick1943.blogspot.com
0 Response to "How To Find The Difference Between Two Points"
Post a Comment